
Reverse engineering undocumented processors has traditionally required months of manual work. In this article, Faraday researchers share how a hybrid AI-assisted pipeline recovered a proprietary instruction set architecture, generated a working Ghidra processor specification, and transformed unreadable firmware into actionable security research.
By Gastón Aznarez and Dan Borgogno, Faraday Security. A companion to our talk at Ekoparty’s first international edition (Miami, 2026).
Behind a surprising number of everyday devices, from cars to medical devices, security cameras, routers, and connected toys, there is a chip running code that nobody outside the manufacturer can read. When one of those devices has a flaw, the only way to find it before an attacker does is to look at that chip from the inside.
The catch is that many of these chips run on proprietary instruction sets with no public documentation. The industry calls this “security by obscurity,” and in practice it protects no one: well-resourced attackers reverse it anyway. The only people left out are the independent researchers who might have warned you first. There are too many chips and too few researchers.
This is the story of a tool we built to change that ratio, and what it taught us about where AI actually helps in low-level reverse engineering.
The wall

It started, as these things do, with curiosity. We bought a connected vape (a cheap consumer gadget with a touchscreen, Bluetooth, and a companion app) and took it apart to see what was inside. The interesting part was the main chip, a JieLi SoC. After a detour through the hardware (the firmware turned out to live inside the chip, not on the external flash, so we built a small circuit to coax it out), we had the firmware in hand.
Then we opened it in Ghidra, the standard reverse-engineering tool, and got a wall of raw hex. No instructions, no functions, nothing to read.
Here is why. A program on disk is just bits. Turning those bits into something a human, or a decompiler, can read requires knowing the rules of the chip’s Instruction Set Architecture (ISA): which bits are the operation, which are registers, which are numbers. For mainstream chips like x86, ARM, and MIPS, those rules are public and ship with Ghidra. This chip runs pi32v2, a proprietary architecture from the vendor. No public spec, no Ghidra support, no real tooling. We had the firmware. We couldn’t read it.
A Rosetta stone in the disassembly
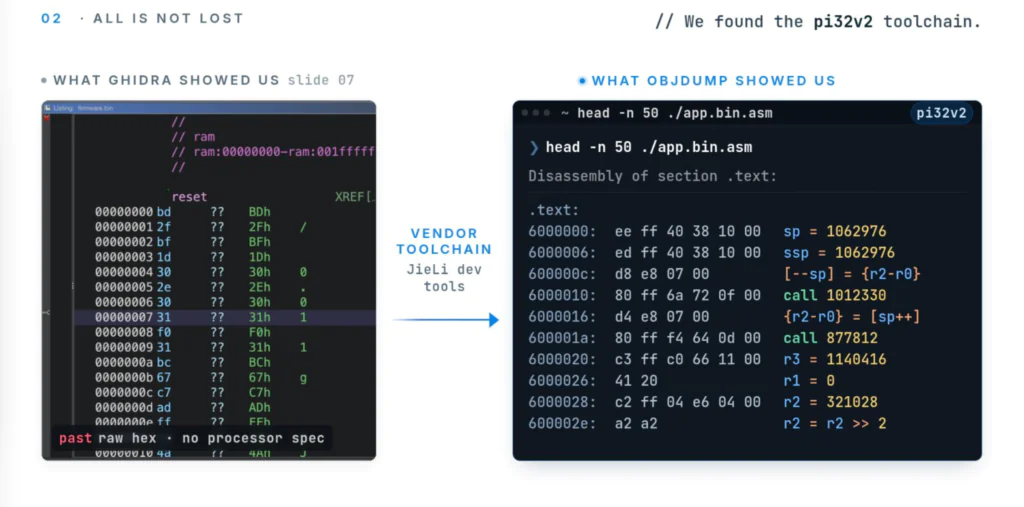
We did have one foothold. The vendor’s own toolchain included an objdump, a disassembler that prints each instruction’s raw bytes next to a human-readable mnemonic like add r0, r1, r2. That is a Rosetta stone: the same instructions written in two scripts at once, the unknown one (the bits) beside a known one (the mnemonics). We just didn’t have the rules that map between them.
We could have reverse-engineered the vendor’s toolchain to extract those rules directly, but that is a whole second project. Instead we bet on the disassembly itself, and on AI to read it.
Modern language models are good at two things that used to require a human expert: recognizing patterns in text that looks like nonsense, and reasoning about unfamiliar structures to deduce what they mean. Recovering an ISA from disassembly is exactly that kind of problem. The promise was to automate most of the work a specialist used to do by hand, and to generalize to chips no tool has ever supported. What took months might take days.
That was the promise. The reality taught us something more specific.
The solution: a hybrid pipeline
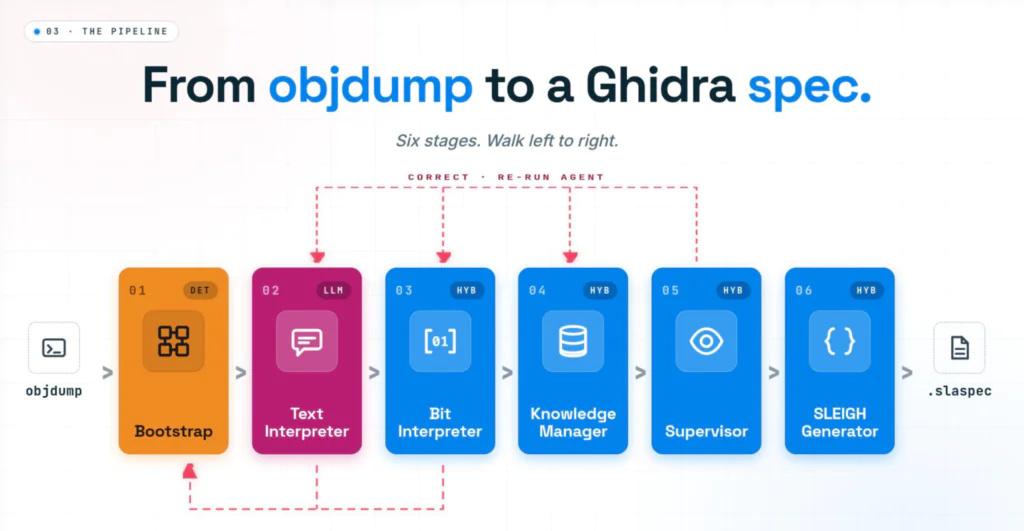
We built a pipeline that takes disassembly in and produces a Ghidra processor specification (a SLEIGH file) out. It is organized as a fixed sequence of stages, each with a narrow job. Some stages are plain deterministic code; some are a language model prompted for one specific task. Crucially, the orchestration is deterministic: the code decides what runs next, not the models. Each stage below links to its full writeup in the project wiki.
Six stages:
- Bootstrap groups the instructions that share an encoding and discards duplicates, with pure pattern-matching and no AI. Stack a handful of the same kind of instruction and compare them column by column: the bits that never change are the opcode, the bits that vary are the operand fields. For example, add x1, x2, x3 and add x5, x6, x7 share the same fixed opcode bits and differ only where the register numbers sit, so they land in one cluster.
- Text Interpreter (LLM) reads the mnemonics and works out the meaning. Handed that cluster of adds, it returns the shape add {REG1}, {REG2}, {REG3} and labels the operands: one destination register and two sources.
- Bit Interpreter maps each operand to specific bit positions, and it is the hardest stage. Take the samples where the first operand is x5, then the ones where it is x11, then x19, and see which bits stay fixed inside each group: the positions that hold steady across all of them are where that register field lives (a five-bit slot, for 32 registers). And when one cluster secretly holds two encodings, it splits them. A batch of loads that looked uniform splits on a single selector bit into a stack-pointer-relative form and a register-relative form.
- Knowledge Manager accumulates everything into a growing, structured description of the architecture. It records add as an ALU operation over three registers, adds any newly seen registers to the register file, ticks coverage upward, and raises a flag if a new cluster’s opcode collides with one it has already learned.
- Supervisor decides what happens next: accept the result, re-run a stage with feedback, escalate to a human, or stop. On our LEGv8 run it caught a branch whose offset field matched almost none of the samples and sent the cluster back for another pass instead of committing a broken encoding.
- SLEIGH generation turns the description into a Ghidra spec, compiles it, reads the compiler’s errors, fixes them, and repeats until it is clean. A byte load like ldurb took four of these compile-and-fix rounds before its zero-extension semantics compiled cleanly; most instructions passed on the first try.
Here is the lesson, and it is the most important thing we found. Our first instinct was to put an LLM on every stage. It failed in a very consistent way: models are excellent at semantics (what an instruction means) and unreliable at bit arithmetic (which exact bits, how wide, in what order). They would confidently place a field in the wrong position even with the evidence right in front of them. So everywhere the work was numeric, we replaced the model with deterministic code. The Bit Interpreter now finds field boundaries mathematically and only calls the model when the math is genuinely ambiguous, and even then, for a judgment, not a calculation.
We set out to build a multi-agent AI system. We ended up with a hybrid: AI for the reasoning, deterministic code for everything countable. The “multi-agent AI” framing was the marketing; the hybrid is the engineering.
Does it work?
To check correctness, we ran it on MIPS, a well-documented architecture where we already know the right answer. The pipeline recovered about 98% of the instructions in our test binary, and, telling given the lesson above, roughly 91% of that work was done with no AI calls at all. The deterministic core carries the load; the model is the specialist you call in for the hard remainder.
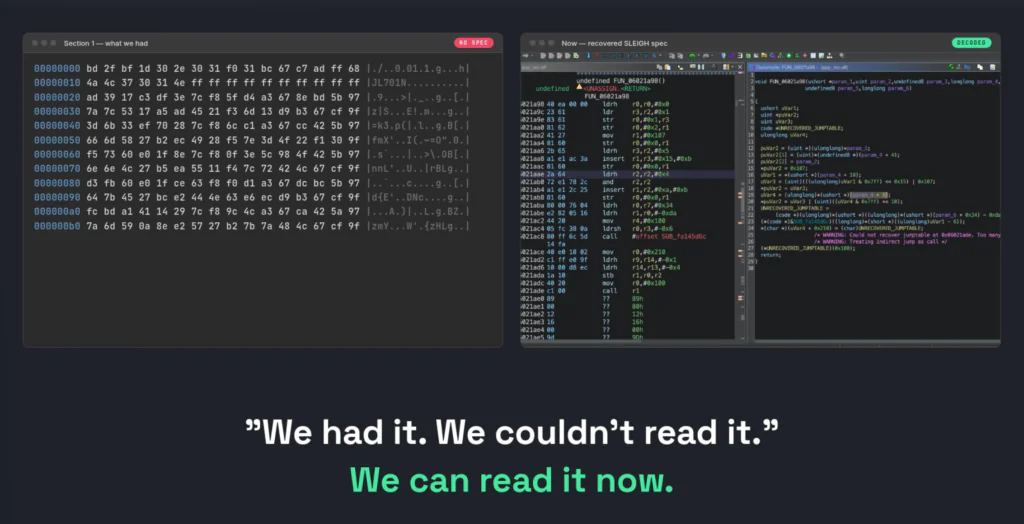
Then the real target: pi32v2, the vape’s chip. In about two and a half hours and roughly $25 of compute, the pipeline produced a Ghidra plugin that compiles and loads. The firmware that was a wall of hex is now a navigable program: functions, control flow, decompiled pseudo-code. The difference between raw hex and a program you can read is the difference between a locked door and an open one, and we opened it on a chip that had no tooling at all.
We were not the only ones on this architecture. While we were building the pipeline, Damien Cauquil at Quarkslab independently reverse-engineered the same pi32v2 family by hand, working from the vendor’s objdump output just as we did, and published an improved Ghidra SLEIGH spec. Their writeup is worth reading: weeks spent poring over disassembly listings to pin down each instruction and work out how its operands were encoded. That painstaking manual process is exactly what our pipeline sets out to automate. Two independent efforts landing on the same architecture at the same time, one by hand and one automated, is about the best confirmation we could ask for that the problem, and the results, are real.
Like any technique, it has an envelope, and knowing it is part of using it well. The pipeline builds on the vendor’s own disassembly, so the richer that input, the richer the result. It already handles chips with mixed instruction sizes, as pi32v2 showed; the open frontier is architectures like x86, where you cannot tell where one instruction ends without decoding it first. That is the next problem to solve.

What this actually means
The standard view is that AI helps reverse engineering at the top, naming functions and summarizing code, while the low-level bit work stays human. What we found is that the boundary is not where people think. An AI can operate at the semantic layer of binary analysis on an architecture it has never seen, as long as the numeric layer is handled deterministically alongside it. The boundary moved down, toward the bits. It just did not reach all the way.
That matters beyond one chip. What is changing in 2026 is not that AI finds magic bugs; it is the economics of the work. A task that used to pin a researcher for months can now be largely automated, and an orchestrated system can cover far more ground than one person in the same time. With too many chips and too few researchers, coverage is the whole game.
Get it, and what’s next
The tool is open source at github.com/infobyte/isa_recovery. It takes disassembly from any toolchain and outputs a Ghidra SLEIGH spec. Treat it as a research proof of concept rather than a finished product: it is an active work in progress, and we are releasing it early on purpose, because the approach is the contribution and we want others to build on it.

The next direction removes even the toolchain requirement. Instead of disassembly, feed the pipeline the processor’s observed behavior: run candidate instructions and watch what changes in registers and memory. The semantics come straight from the silicon: same pipeline, no vendor tools needed.
And there is a piece of math we left out here: a single small equation that explains most of the number-encodings we saw across very different chips. That deserves its own post, and it will get one.
Curious about how Faraday combines offensive security expertise with AI-driven research? Talk to our team and discover how we help organizations uncover security risks before attackers do.
More about what we do: