Estas son las vulnerabilidades que hemos revelado durante 2022
El software de código abierto aumenta su presencia en centros de datos, dispositivos de consumo y aplicaciones; además, su comunidad sigue creciendo. A pesar de que el código está disponible, persisten los problemas de seguridad de memoria en el software popular. Nuestro equipo de investigación comenzó una nueva búsqueda para encontrar y notificar vulnerabilidades en los proyectos de código abierto que utilizamos a diario. Esta es la segunda parte de ese trabajo, donde comparten con nosotros la estrategia que utilizaron para encontrar estos fallos: fuzzing guiado por cobertura.
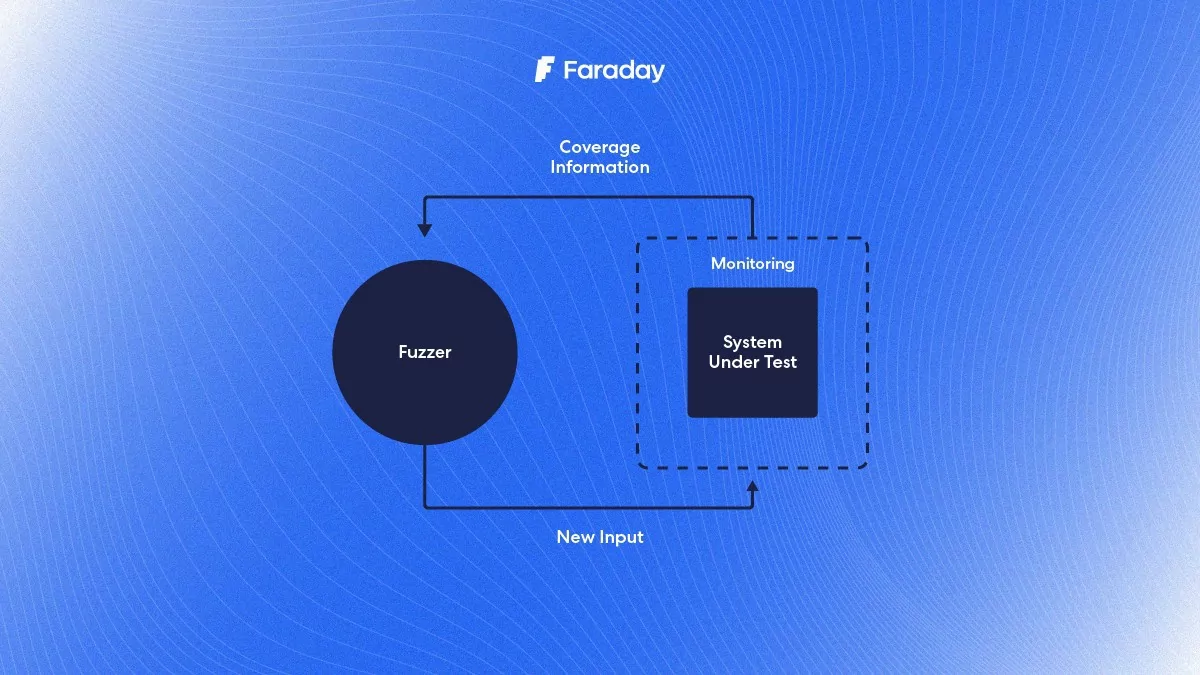
En primer lugar, repasemos los fundamentos del fuzzing. La idea básica es generar casos de prueba automáticamente. Para ello, partimos de un conjunto de entradas creadas a mano y dejamos que el fuzzer genere otras nuevas. El fuzzer ejecutará el programa alimentándolo con una entrada del pool con una mutación aleatoria aplicada. Entonces comprobará si el programa falla y, si lo hace, guardará dicha entrada para que podamos analizarla más tarde. Si el programa no falla, seguirá iterando aplicando mutaciones a las entradas y ejecutando el programa. Cuando un fuzzer se limita a ejecutar entradas mutadas aleatoriamente de esta forma, sin hacer un seguimiento del comportamiento del programa analizado, se denomina fuzzer de caja negra. Ya que está tratando al programa como una caja negra que sólo acepta datos y puede fallar o no, dependiendo de los datos que se le suministren.

Pasemos a discutir la idea de utilizar la cobertura para ayudar al fuzzer. Esta estrategia consiste en modificar el programa utilizando una técnica conocida como instrumentación para obtener información sobre qué partes del código son ejecutadas por una entrada (normalmente denominada cobertura). Sólo aquellas entradas que aumenten la cobertura se utilizarán para el fuzzing posterior, permitiendo probar un programa de forma más exhaustiva. Dado que la instrumentación del programa requiere un análisis ligero del mismo, esto se conoce como fuzzing de caja gris.
Para instrumentar un programa, el compilador modifica las instrucciones generadas después de cada salto condicional. Introduce un fragmento de código que realiza un seguimiento de las ramas a medida que se ejecutan por cualquier entrada dada. El fuzzer utiliza esta información durante el tiempo de ejecución para detectar entradas interesantes que ejercitan nuevas rutas de ejecución, aumentando así la cobertura del programa. Para entender por qué esto es importante, consideremos la siguiente función:
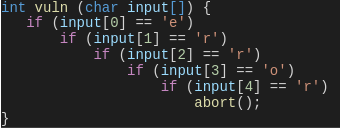
La probabilidad de generar una entrada que llegue a la llamada a abort() mutando aleatoriamente las entradas iniciales es muy baja. Sin embargo, si el fuzzer construye nuevas entradas basadas en las que previamente entraron en cada sentencia condicional, el número de casos que deben generarse para llegar a abort() disminuye drásticamente. Esta es la razón por la que la retroalimentación de cobertura permite al fuzzer ejercitar rutas interesantes que son disparadas por entradas complejas de manera más eficiente.
Aquí está la lista de las vulnerabilidades que hemos encontrado recientemente utilizando esta técnica:
- CVE-2022-0890: Derivación de puntero nulo en MRuby
- CVE-2022-0632: Derivación de puntero nulo en MRuby
- CVE-2022-0481: Derivación de puntero nulo en MRuby
- CVE-2022-0368: Lectura fuera de límites basada en heap en Vim
- CVE-2022-0326: Derivación de puntero nulo en MRuby
- CVE-2022-0319: Lectura fuera de límites basada en heap en Vim
- CVE-2022-0240: Derivación de puntero nulo en MRuby
- CVE-2022-0128: Lectura fuera de límites basada en heap en Vim
¿Le interesan nuestros productos? Consulte nuestra versión gratuita, aquí.




