These are the vulnerabilities we’ve disclosed during 2022
Open-source software increases its presence in data centers, consumer devices, and applications; also, its community continues to grow. Despite the code being available, memory safety issues persist in popular software. Our research team started a new quest to find and report vulnerabilities in the open-source projects we use every day. This is the second part of that job, where they share with us the strategy they used to find these bugs: coverage guided fuzzing.
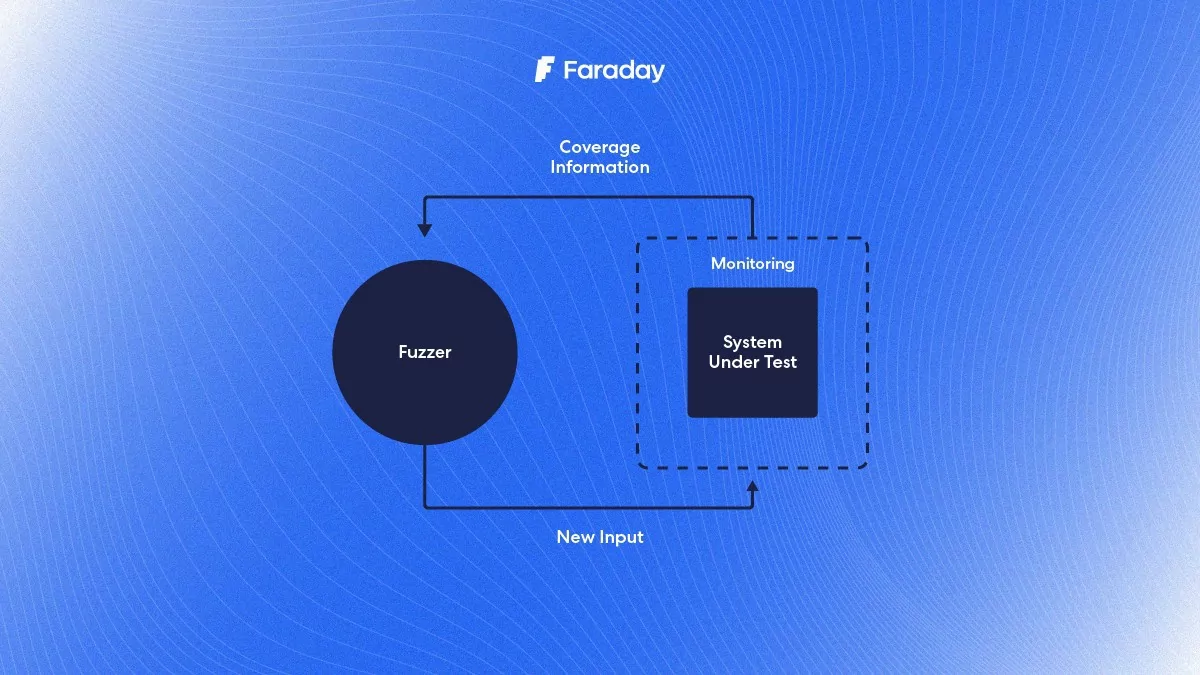
First, let us go through the basics of fuzzing. The basic idea is to generate test cases automatically. We do this by starting with a pool of hand-crafted inputs and we let the fuzzer generate new ones. The fuzzer will execute the program feeding it an input from the pool with a random mutation applied to it. It will then check if the program crashes and, if it does, it will then save said input so we can analyze it later. If the program doesn’t crash, it will just keep on iterating by applying mutations to the inputs and executing the program. When a fuzzer just executes randomly mutated inputs like this, without keeping track of the behavior of the program under analysis, it is called a black-box fuzzer. Since it is effectively treating the program as a black box that just accepts data and can either crash or not, depending on the data being fed to it.

Let’s move on to discuss the idea of using coverage to assist the fuzzer. This strategy involves modifying the program using a technique known as instrumentation to get feedback about which parts of the code are executed by an input (usually referred to as coverage). Only those inputs that increase coverage will be used for further fuzzing, allowing to test a program more thoroughly. Since instrumenting the program requires some lightweight program analysis, this is known as grey-box fuzzing.
To instrument a program, the compiler modifies the instructions generated after each conditional jump. It introduces a piece of code that keeps track of the branches as they are executed by any given input. The fuzzer uses this information during runtime to detect interesting inputs that exercise new execution paths, thus increasing the program coverage. To grasp why this is important, let’s consider the following function:
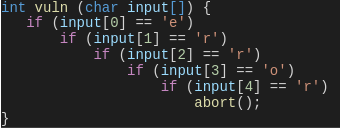
The probability of generating an input that reaches the call to abort() by randomly mutating the initial inputs is very low. However, if the fuzzer constructs new inputs based on the ones that previously entered each conditional statement, the number of cases that must be generated to reach abort() decreases drastically. This is the reason why coverage feedback allows the fuzzer to exercise interesting paths that are triggered by complex inputs more efficiently.
Here is the list of the vulnerabilities we recently found using this technique:
- CVE-2022–0890: NULL pointer dereference in MRuby
- CVE-2022–0632: NULL pointer dereference in MRuby
- CVE-2022–0481: NULL pointer dereference in MRuby
- CVE-2022–0368: Heap-based out-of-bounds read in Vim
- CVE-2022–0326: NULL pointer dereference in MRuby
- CVE-2022–0319: Heap-based out-of-bounds read in Vim
- CVE-2022–0240: NULL pointer dereference in MRuby
- CVE-2022–0128: Heap-based out-of-bounds read in Vim
Are you interested in our products? Check out our free version, right here.